这是用户故事系列的第六篇。
一条需求敢跳出来,基本上就能被化成一条用户故事,看完一二三四五,上山打老虎都不怕,这个似乎已经不太难了。
难的是,项目或产品的第一天,给一张白纸:“请列出有哪些故事”。那个时候其实不是大脑空空,而是有千言万语就是说不出。
前年做另外一件事情的时候偶然得到一种方法,去年到今年用在一个敏捷项目上,果然很舒服地列出了大量故事,后来的开发过程证实它们都满足独立交付、可测试、耦合低等特点,属于好故事之列。
引子
这件事情其实在之前的博客中已经多次提到了,就是软件项目的造价管理。注意这里提到的是项目,而非产品研发。项目就是那种一手交钱一手交货的甲乙方项目。
之前曾经提到过:无论有多少种方法对优先级进行排序,作为产品而言,都永远应该把最体现差异化价值观的功能置于万事之前。
这里要说的则是:无论有多少管理方法,作为项目而言,都永远应该把造价估算置于万事之前。
这个前不是一般的前,最好能用几张A4纸的篇幅就搞定,因为一般老板刚去签订合同的时候,手里没有需求,没有设计,没有故事,就这么几张纸。当然另一个尴尬的事情则是:即使有很厚的需求文档了,也仍然没有方法知道要多久才能完成项目,真的很愁人。
其实这两件事说的是一件事:如何在早期列出具有某种表征意义的需求列表。
甚早期的用户故事生成方法
在之前的博客详细描述过了,这里只从产生和组织用户故事的角度谈谈,详情请看文末的链接。
在我们的开发工作中一共有两类东西要开发,一种是数据,一种是操作。
所谓数据,就是比如要编写一个CRM,其中有“用户、角色、权限”这三种东西,就是要管理的数据,这里权且记下用户有“3个史诗故事”要管理。
所谓操作,就是对用户,应该有增、删、改、查、加入角色……这些称之为操作,这里权且记下对用户,用户会有“5个用户故事”。
下面是我们的实际项目的局部截图,课本是史诗,蓝色是故事带括号和加号的是两个合并的故事,箭头是增强请参考上篇故事分类:
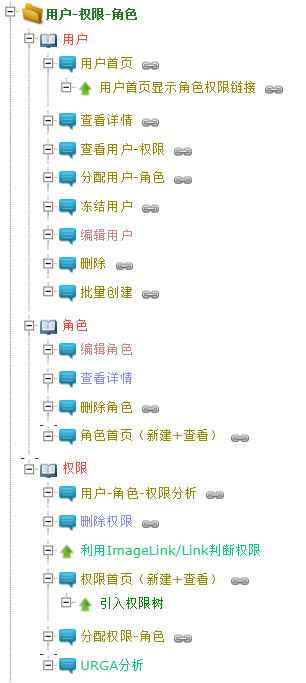
史诗都是名词,都是要被管理的核心信息,而且是用户可以理解的信息;
故事都是动词,都是用户平日里使用软件产品所进行的业务操作;
最后一个小贴士是每个史诗故事平均有7个左右的故事,少于4个要怀疑是不是史诗,多于10个要怀疑是不是应该拆分新的史诗了。
最后这条是NESMA 20年来的经验数据,很值得参考但莫较真。比如上面例子分为用户/角色/权限3个史诗对19个故事(平均6.3个),你可以试试再拆拆或合合,效果肯定不如这三个干净。只能说他们20年真没白干。
这个方法听起来很水很模糊,但因为开过几次造价估算培训课,在我经手的3次培训中,通过短短1天培训后,4~5个小组的(最大-最小)/平均 误差只有正负12%,而误差的很大来源,是一个模拟问答环节总是比较嘈杂,很多团队没有注意听答案!@¥#…%!核对需求后,误差可迅速降低到大约一半。课堂练习只有一张A4纸,里边很模糊地隐含了多达90多个用户故事,练习时间只有1小时,能达到如此的一致性已经很满意了。
大尺度上用户故事的组织结构
最早我们在史诗之上,就是无意义的层级式目录结构了,但就像太阳系外有银河系,银河系外有超星系,超星系外有超星系团一样,事情还没有完。
本来以为在史诗之上没有有实际逻辑意义的结构了,但发现“用户角色权限”这三个故事的距离,远远近于其他故事,应该还有一种具有逻辑意义的东西来描述;其他一些史诗故事也发现了这种内聚性,但尚无合理的划分方法将其定义下来。
笔者暂时创造了“故事群”这个概念来描述他们,但没有找到合理的定义,让不同的人可以一致性地划分故事群。
之所以借用功能点分析的概念来产生和组织用户故事,是因为关于用户故事,一直没有非常标准的颗粒度和组织方法;而对于数据、操作,则在接近40年前就开始尝试标准化定义,当前有5个国际标准之多,中国的国家标准也马上出来了。在接受这些标准培训后,不同个体对数据和操作的计数差异,只有不到10%;尚没有任何用户故事的定义能达到如此一致性。
不否认创造和使用敏捷开发的一线员工在定义需求、制定计划、每日跟踪中的经验和权威性,但在大尺度上掌握用户故事的组织结构,以及在甚早期判断项目范围的方面,则正是这一人群的弱项。
敏捷方法需要借鉴已有的外界方法。
为什么不用UML方法?因为本人很不熟悉UML。UML比较适合在大尺度上组织用户故事,但很难在甚早期开展(一张A4,隐含90个故事,1小时估完)。
当然这不会抹杀UML在分析用户故事中的作用,日后或许会请另外一位老师写篇文章《用户故事与UML》,我转发过来作为其中一篇,以求完整。
作者:陈勇
本专栏经作者授权开设,专栏文章未经许可不得转载






